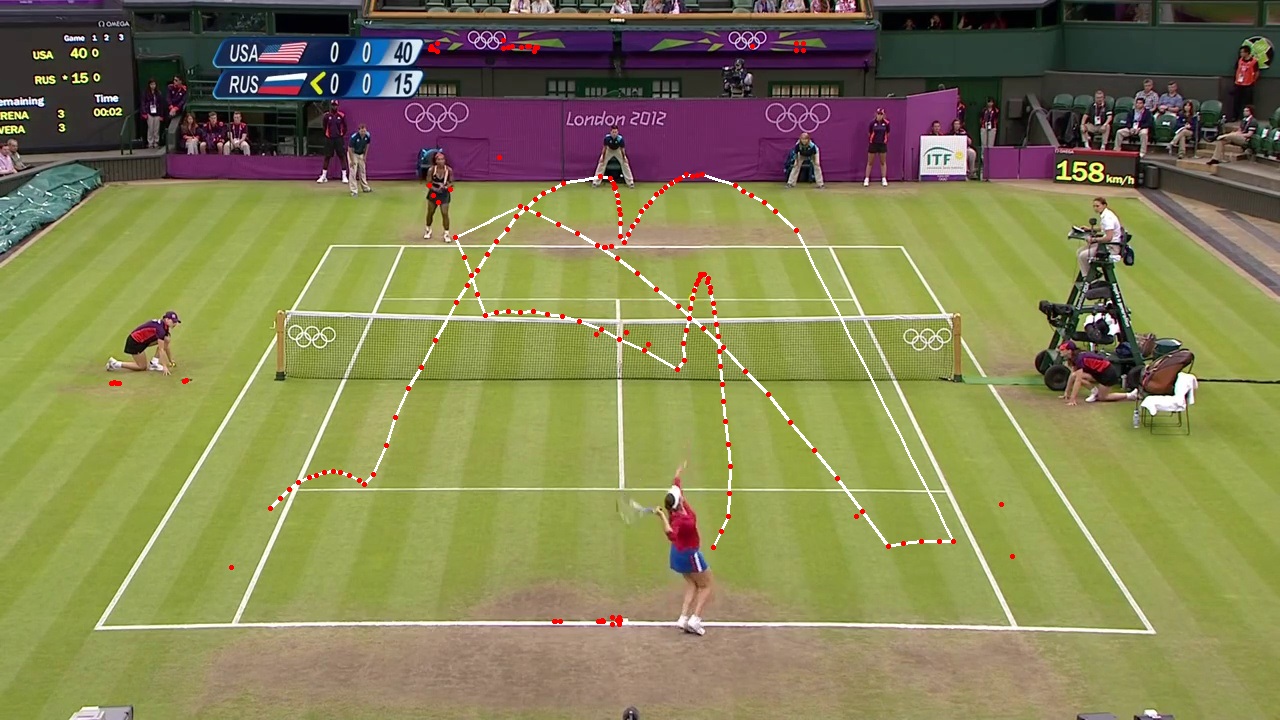
Cílem diplomové práce bylo nastudovat problém detekování trajektorie tenisového míče v obrazovém záznamu a určit vhodné výstupy. Dále navrhnout vhodný přístup k detekci trajektorie tenisového míčku a následném získávání vhodných výstupů z této trajektorie. Navržené řešení implementovat s ohledem na výpočetní čas a zvážit jeho paralelizaci. Na závěr vyhodnotit správnost poskytovaných výstupů a výpočetní čas systému a provést vizualizaci řešení.
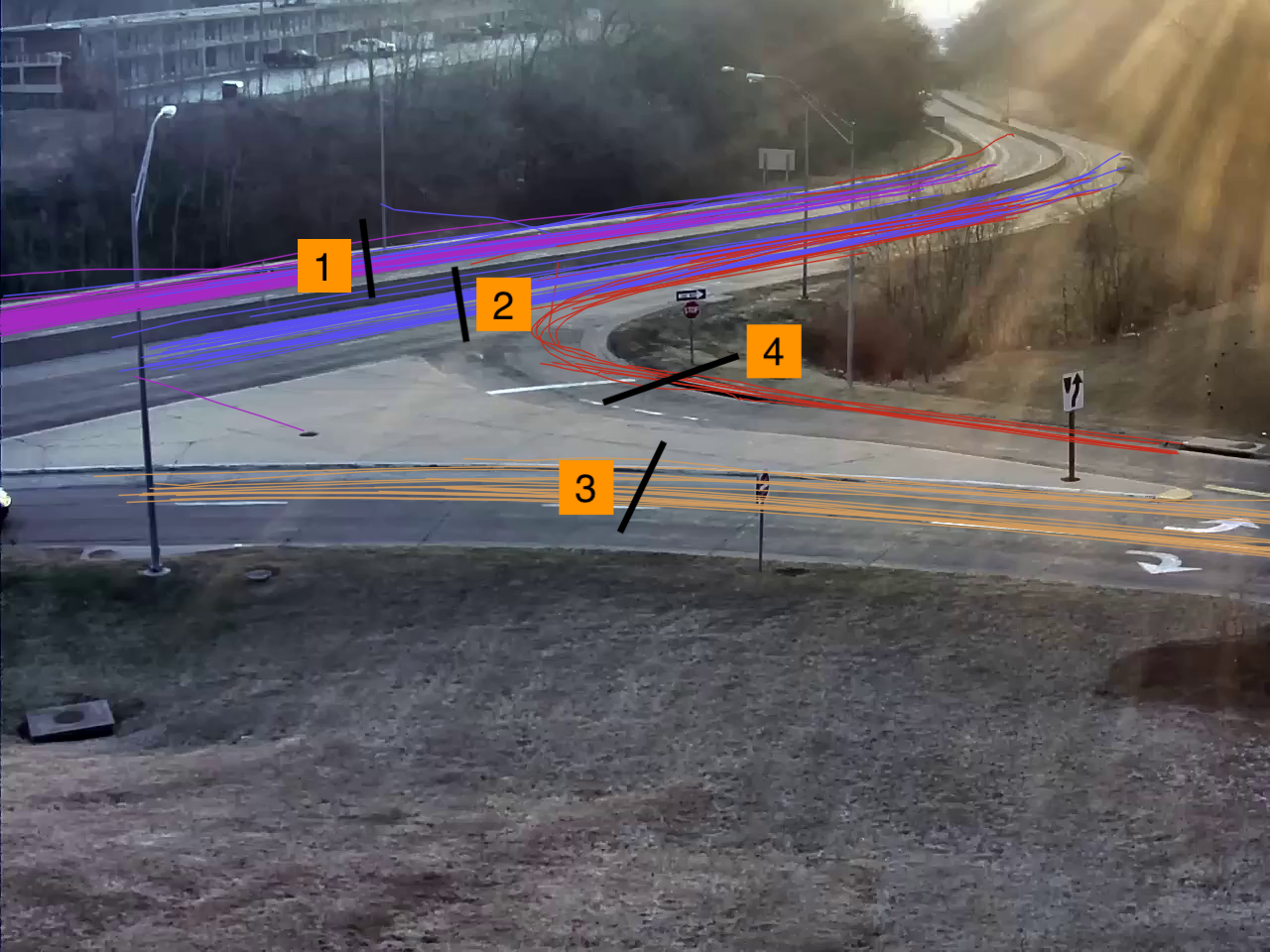
Tato diplomová práce se věnovala vývoji otevřeného softwaru, který umožní automatizaci dopravních průzkumů. Na začátku se diskutovali a objevovali různé přístupy ke sledování více objektů ve videu současně. Následně byl navržen modul, který analyzuje nahrávku ze stacionární kamery a spočítá dopravní prostředky procházející přes oblasti zájmu definované uživatelem. Kvalita modulu byla ohodnocena na několika videích. Bylo zjištěno, že modul funguje dobře a v rámci přípustné chyby, pokud ve výhledu nepřekáží dopravní značení nebo jiné automobily.
Tato bakalářská práce se zabývala strojovým zpracováním výpisu z účtu ve formátu PDF. Jelikož se jednalo o nestrukturovaný dokument, nebylo možné získat informace o účtu a jednotlivých transakcích přímočaře pro další využití. Cílem práce bylo převést zmíněný dokument do strukturovaného formátu. Proto byla nejprve provedena rešerše formátu PDF a existujících metod strojového čtení nestrukturovaných dokumentů, spolu s analýzou veřejně dostupných datasetů. Tyto datasety byly porovnány a diskutovalo se o jejich využitelnosti při řešení dané úlohy. V praktické části byl popsán částečně automatizovaný postup tvorby vlastního datasetu z veřejně dostupných výpisů z účtu. Byla vysvětlena problematika této činnosti a následně byl vytvořen model strojového učení. Výsledkem práce je aplikace pro zpracování výpisu z účtu do strukturovaného formátu.
Odezírání
Autor: Justína Kušpálová
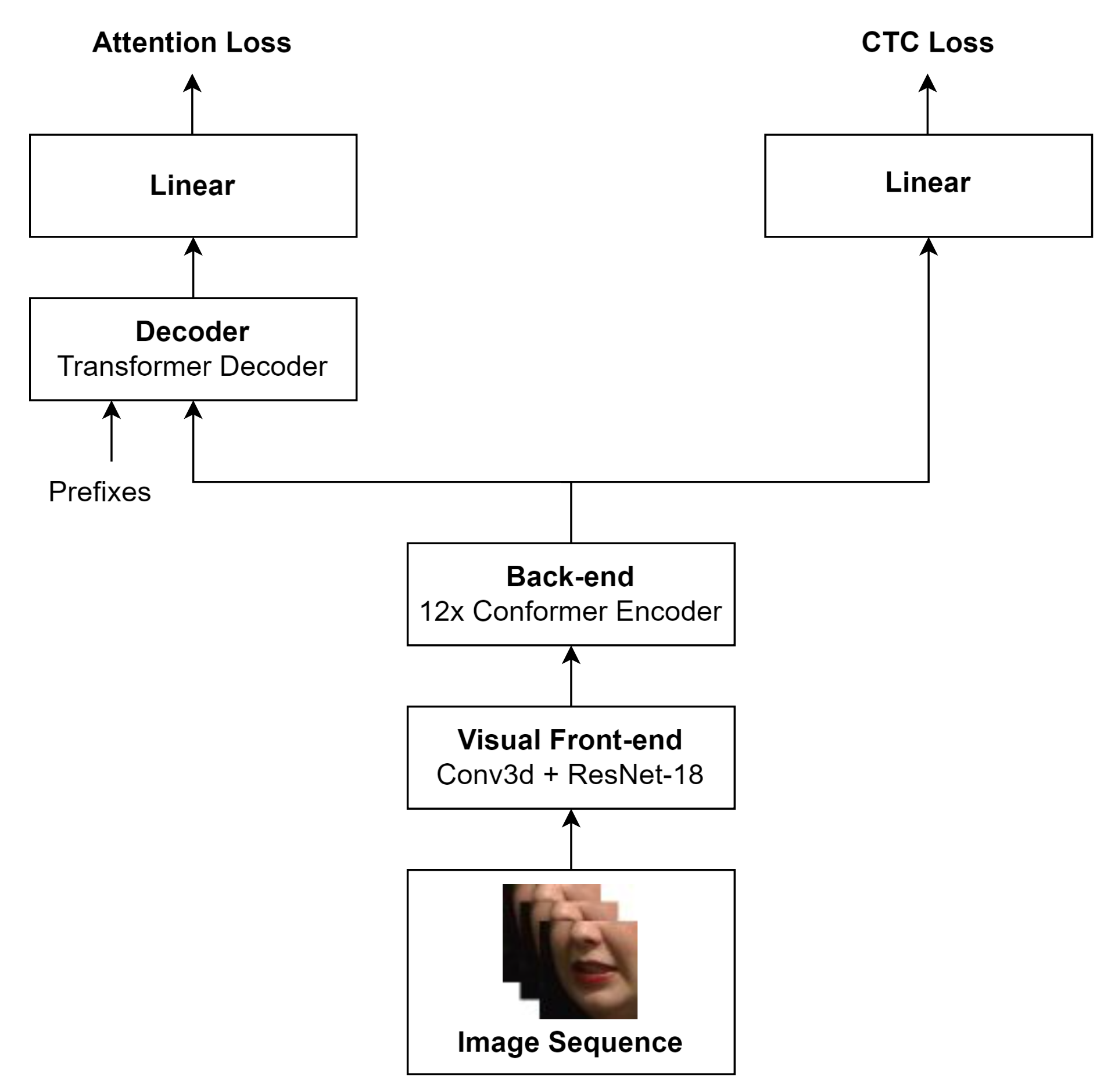
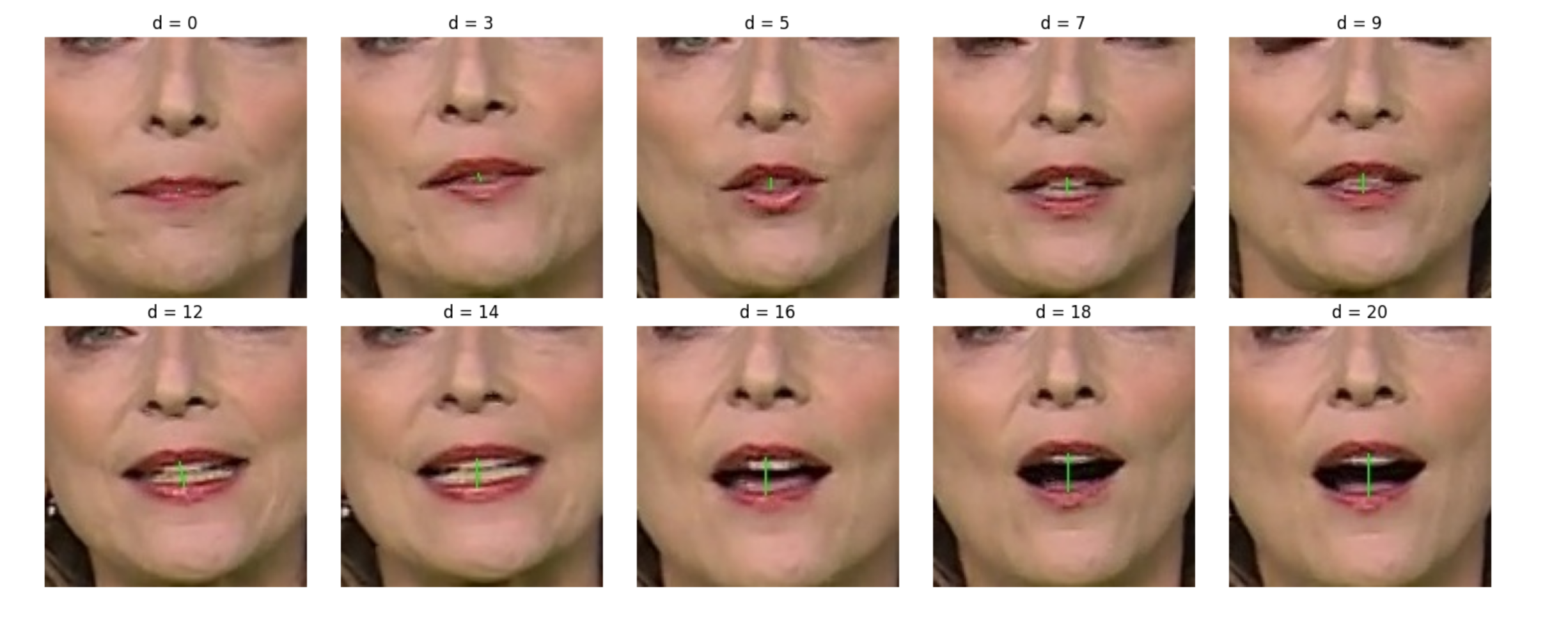
Tato diplomová práce se zabývala automatickým čtením ze rtů v českém jazyce. Rozpoznávanie reči prebieha v nekontrolovanom prostredí, pre ktoré sú charakteristické rôzne svetelné podmienky, rôznorodé pozadie a rôzni rečníci. Všetky spomínané faktory komplikujú vizuálne spracovanie pohybov pier. Na základe existujúcich riešení pre iné jazyky, táto práca implementuje a vyhodnocuje podobné princípy v českom jazyku. Z dôvodu limitovanch zdrojov dát pre iné jazyky ako je angličtina, táto práca taktiež obsahuje proces vytvárania trénovacieho, validačného a testovacieho datasetu v českom jazyku. Vyhodnotenie následne prebieha na novovytvorenom datasete, ktorý vznikol v spolupráci s Českou Televíziou.
V rámci této bakalářské práce byl do aplikace CzechCaptcha přidán modul pro import dat obsahující model pro detekci objektů v obrázku EfficientDet-V4 z frameworku KotlinDL natrénovaný na datasetu COCO. Při nahrávání obrázku do aplikace lze určit, které objekty v něm mají být detekovány. V případě, že model jejich detekci podporuje, jsou na základě jeho výstupů do lokálního úložiště uloženy výřezy obrázku určené pro použití ve výběrové obrázkové CAPTCHA úloze. V opačném případě je původní obrázek použit v nové CAPTCHA úloze pro detekci objektů, v níž testovaný uživatel pomocí obdélníků označuje požadované objekty.
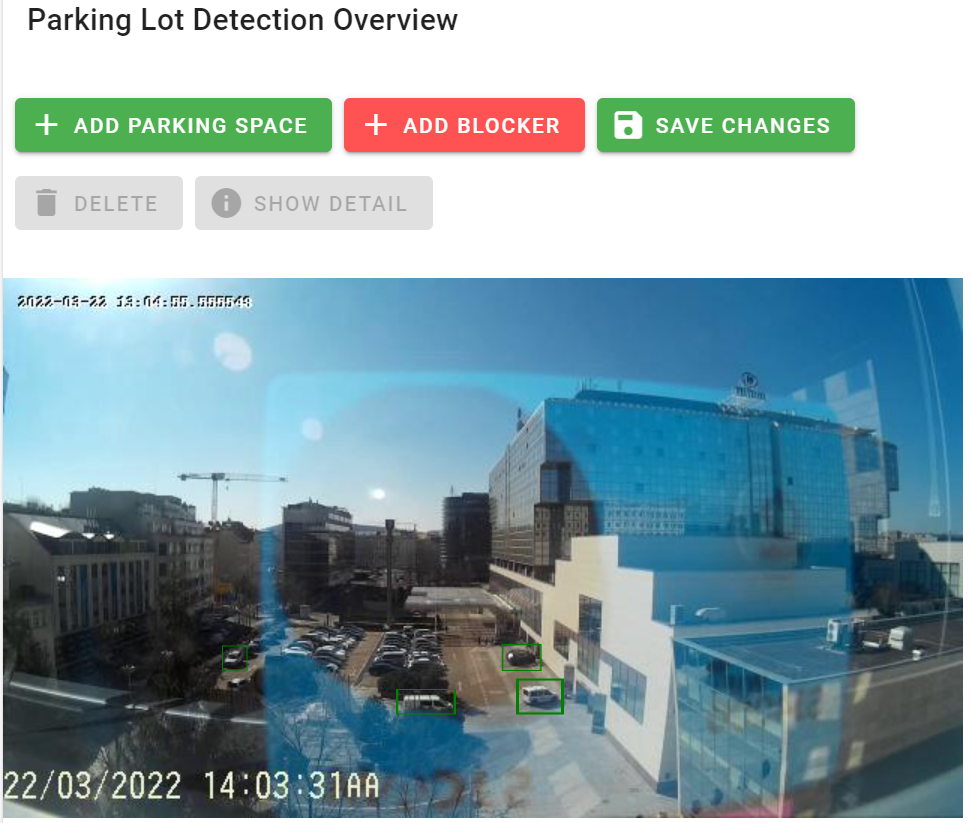
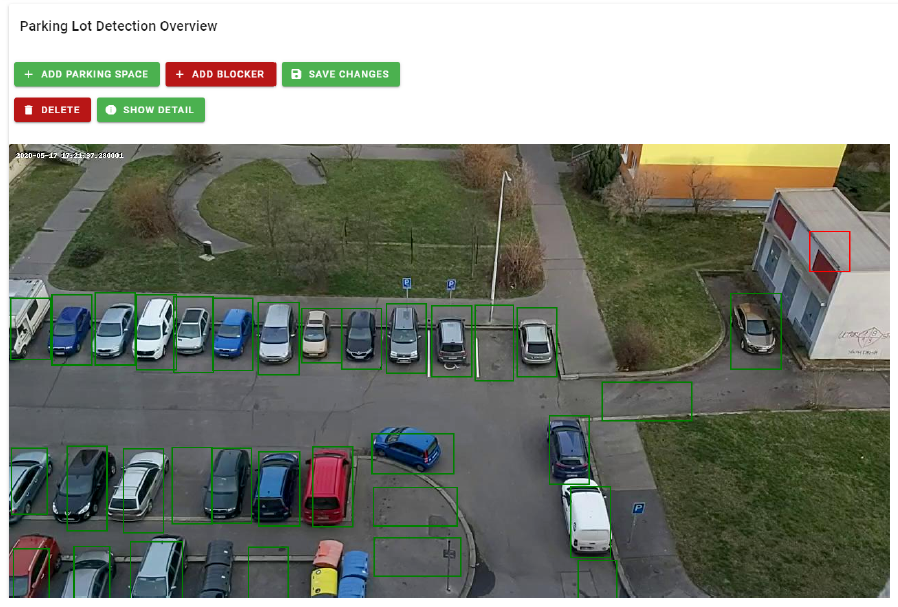
Hlavním cílem diplomové práce bylo navrhnout a implementovat autonomní systém, který extrahuje parkovací místa na parkovišti z kamerového streamu. Tento systém také vyhodnocuje a zaznamenává obsazenost parkoviště v průběhu času. Systém využívá tzv. „processing pipeline“, která periodicky snímá obraz ze streamu a lokalizuje vozidla pomocí detektoru objektů. Systém vykonává vzorkování na základě času s cílem odfiltrovat pohybující se vozidla a případně potvrdit parkovací místa. Potvrzená parkovací místa jsou pravidelně vyhodnocována z hlediska obsazenosti vlastním klasifikátorem.
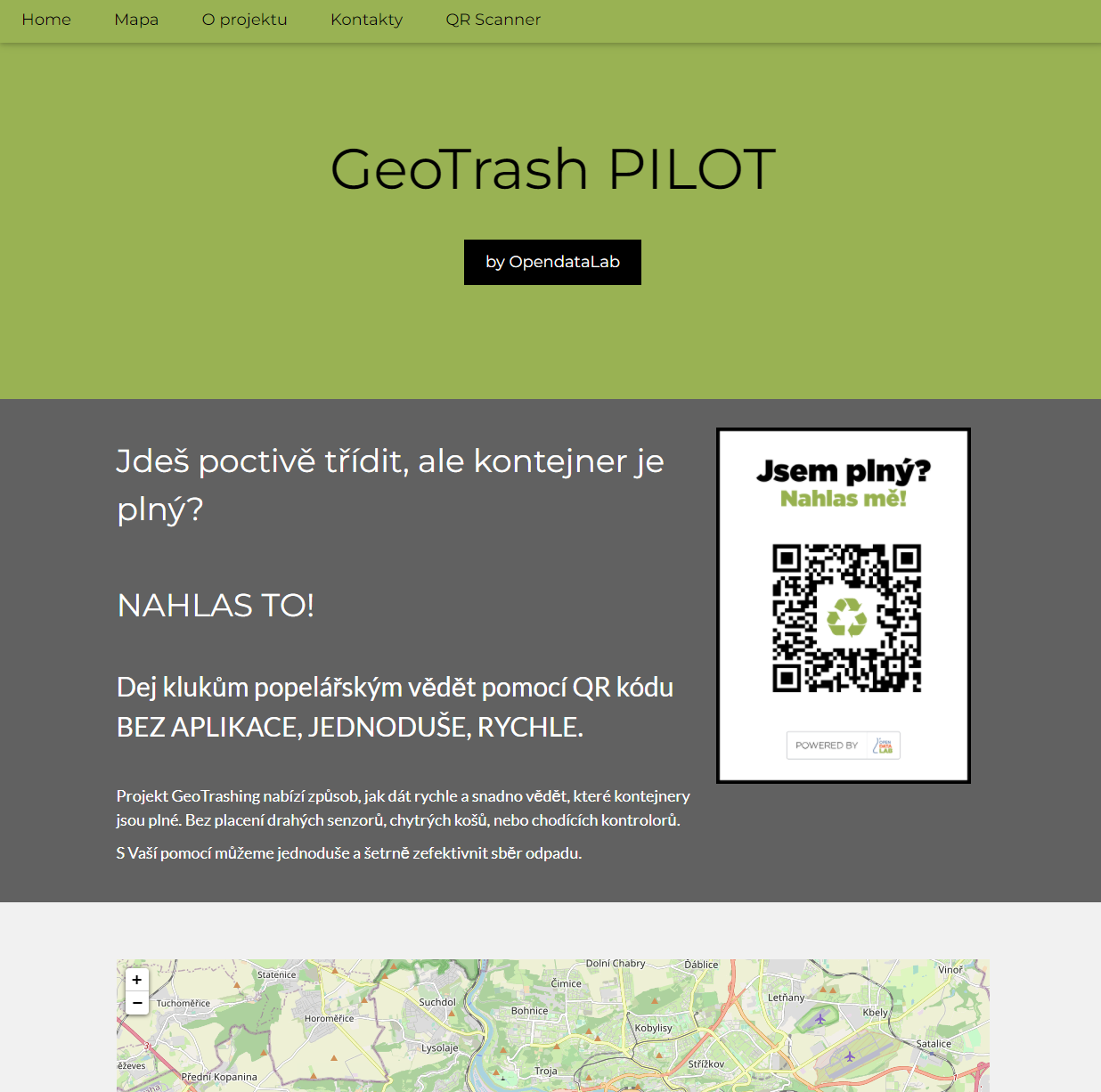
Myšlenka GeoTrashingu vznikla na podzim roku 2019 na hackathonu NKU. Projekt nabízí způsob, jak dát rychle a snadno vědět, které kontejnery jsou plné. V dnešní době existuje řešení na sledování zaplněnosti tříděných odpadových nádob, ale senzory jsou drahé a není možné je umístit všude. Nálepka s QR kódem nestojí moc a je možné ji nalepit takřka kamkoliv. Cílem je tedy nikoliv nahrazovat, ale doplňovat senzory tam, kde to nedává ekonomický smysl.
Bakalářská práce Michala Janečka se zabývá vývojem mobilní aplikace k rozpoznávání kradených obrazů. Nejdříve uvede do problému krádeže uměleckých děl a popisuje současné možnosti jejich rozpoznávání. Dále obsahuje návrh aplikace s třívrstvou architekturou a popis technologií, které byly pro její vývoj použity. Pro rozpoznávání obrazů, které se provádí na serveru, používá algoritmus ORB, který je v práci detailně popsán. Testování bylo prováděno na více datasetech s 1800 obrazy a jednom datasetu obsahujícím přes 9000 obrazů. Při testování s lehce augmentovanými obrazy byla dosažena přesnost okolo 90%, pro více augmentované obrazy zhruba 50%. Výsledný software zahrnuje mobilního klienta, server a databázi a může být použit pro rozpoznávání kradených obrazů.
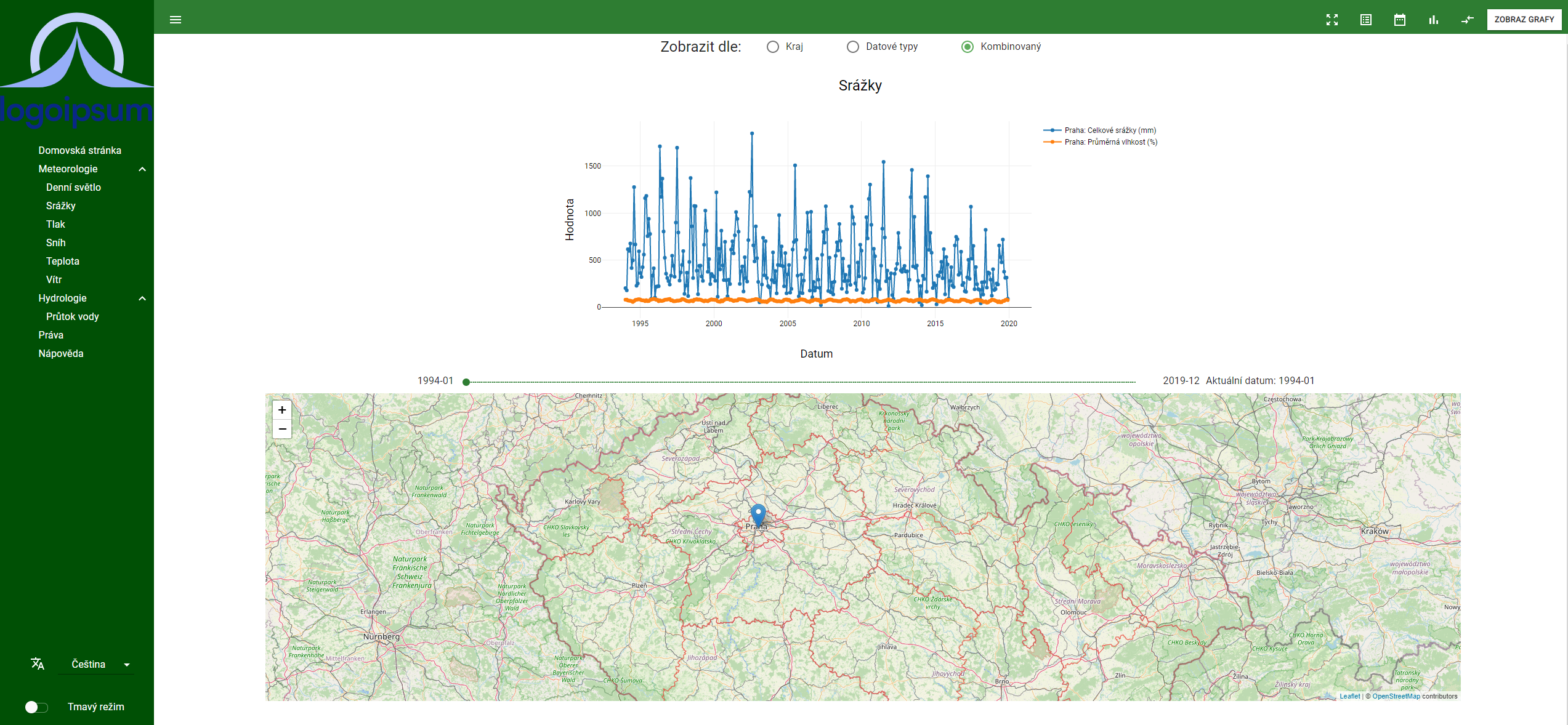
Cílem této bakalářské práce bylo analyzovat veřejně dostupná ekologická data a zvolit vhodná pro vizualizaci dat. Dále se práce zabývá analýzou již existujícich řešení. Práce se následně zabývá návrhem a implementací jednotlivých částí pro získání dat, databázi, backend a frontend. Část pro získání dat se zabývá získáváním dat ze stránek ČHMÚ.
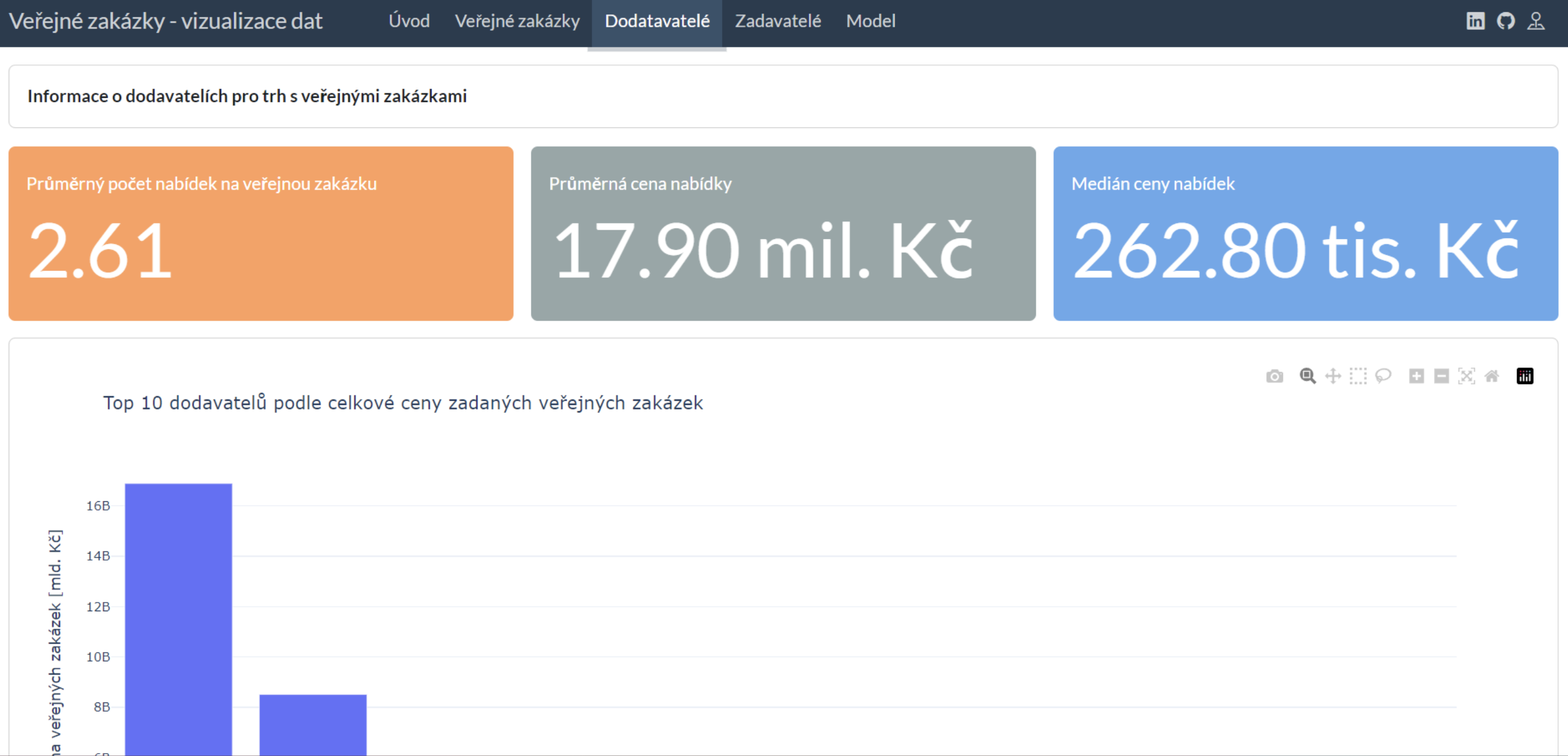
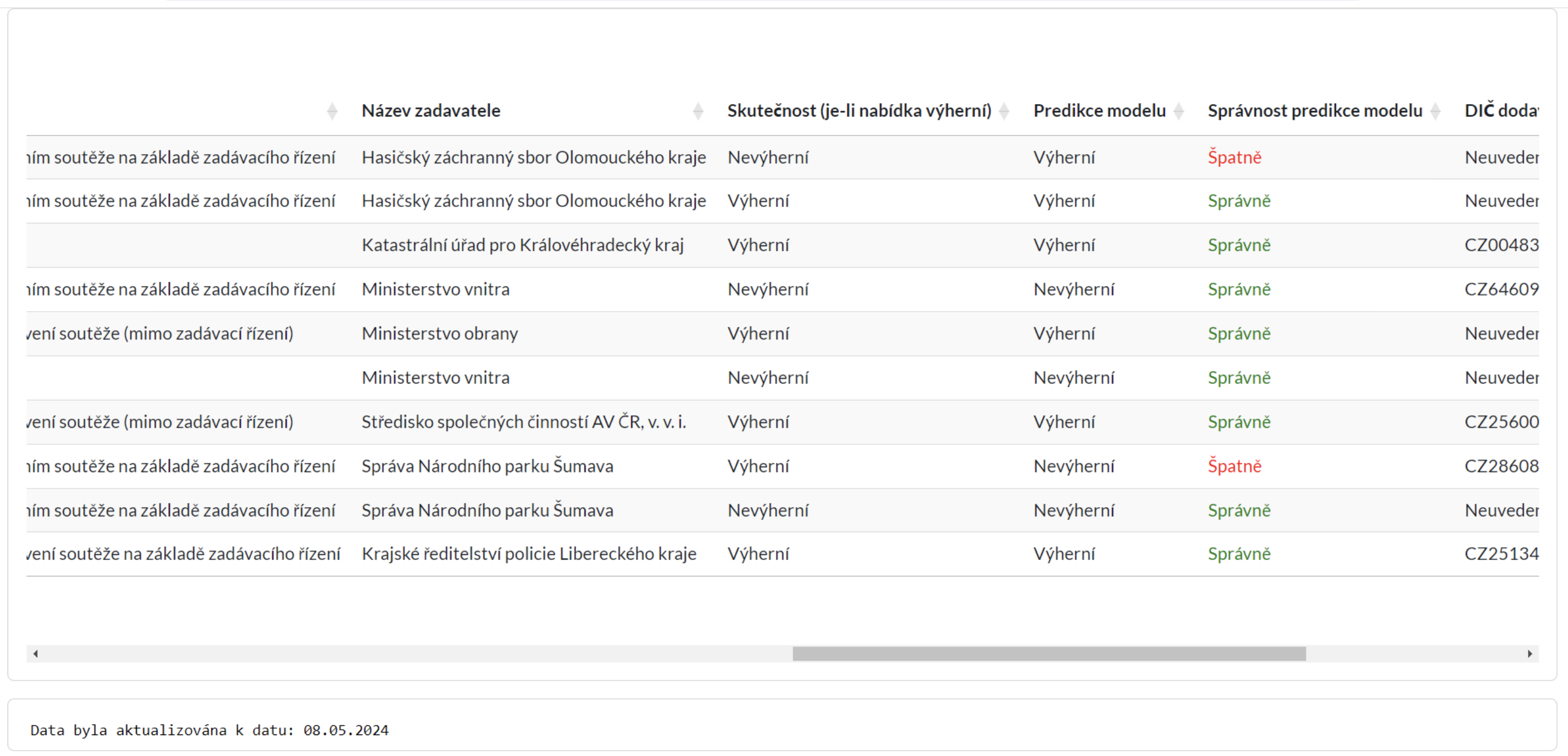
Cílem této bakalářské práce byla podrobná analýza a následná vizualizace existujících dat, respektive vizualizace aktuálního stavu trhu s veřejnými zakázkami v České republice. Je zde provedena explorační analýza, při které jsou vizualizovány základní popisné statistiky. Dále je v této práci využit přístup strojového učení, při kterém byla nejprve data předzpracována, včetně použití metod ”Feature Engineering“. Následně bylo na těchto datech natrénováno několik modelů pro predikci výherní nabídky a pomocí ladění hyperparametrů byl vytvořen finální model. Poté se využije tento model k prozkoumání vlivu jednotlivých příznaků a hledání anomálií, a to v kombinaci se shlukovacím algoritmem DBSCAN. Nakonec jsou všechny tyto poznatky zpracovány a vizualizovány formou webových reportů, a tím pádem jsou k dispozici široké veřejnosti.